Online Operations Manual
Table of Contents
Scientific results
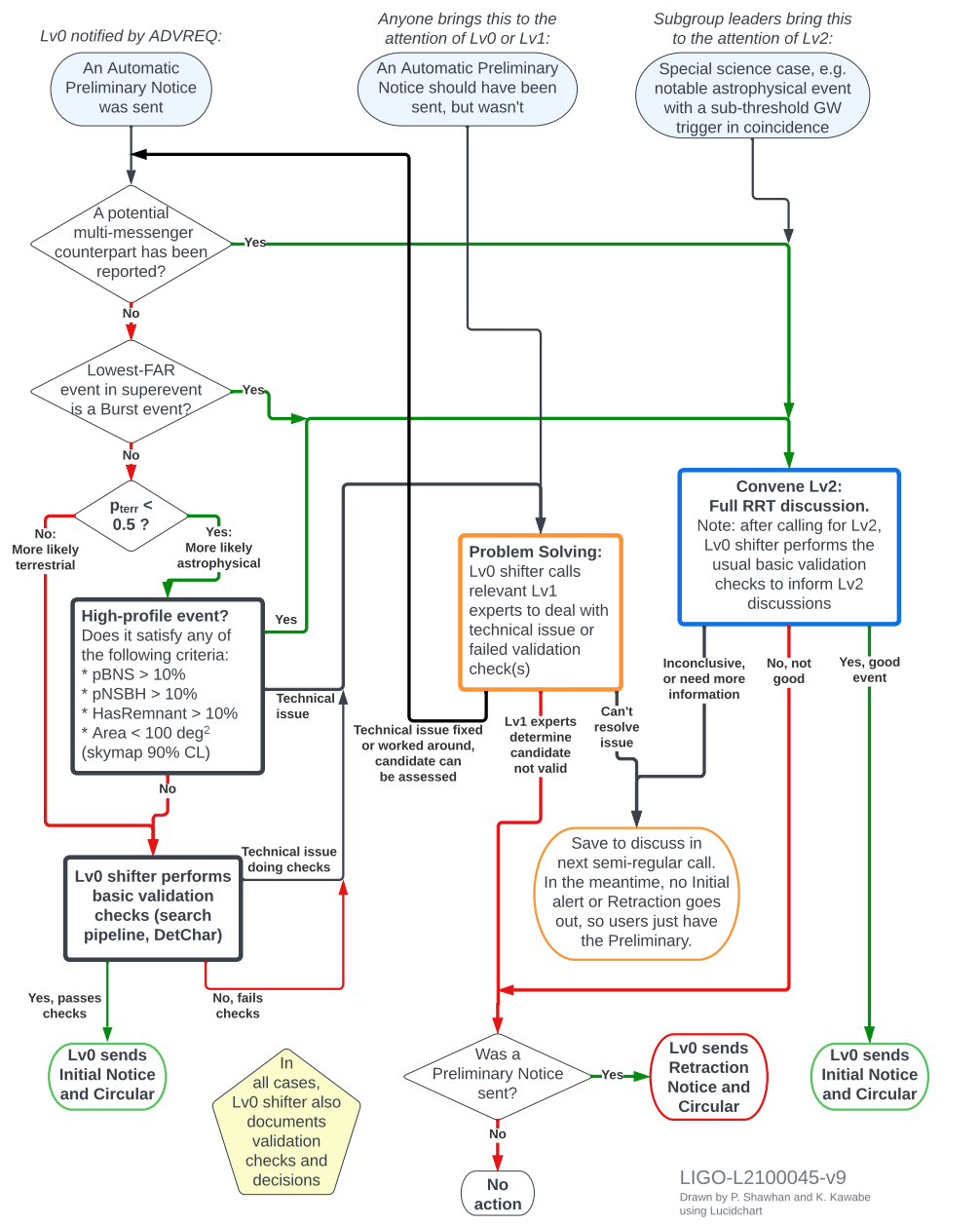
What happens when there is an alert (see O4 policy, and the diagram at the bottom for details)
-
Send out an preliminary GCN notice automatically (machine-readable contents)
-
Get a notification from GraceDB server (via email or SMS)
This notification system was in place at the time of O3 -
get on RRT (Rapid Response Team) call held in Teamspeak EM channel
This team consists of:- Team Leads: One Site Advocate from each site. Serve as final arbiter in the event of a dispute.
- Operators on shift from each active detector.
- An EM Advocate.
- One pipeline expert from each pipeline (including one person on gstlal shift)
- One detchar expert per detector
- A low-latency infrastructure (GraceDB) expert.
This call is NOT required when an event is vanilla BBH (i.e. significant but not EM bright), but it is safe to always get in the EM channel and see how it goes. The members assess the validity of a detected trigger based on the data quality/pipeline status. If gstlal finds the triggers, it would be likely for us to be asked for opinions. The members contribute to drafting a GCN circular (human-readable contents) during the call.
-
Send out the initial GCN circular.
The RRT call ends with sending the circular and notice. In the case of vanilla BBHs, the circulars will be sent out immediately? (this is probably fluid and can be changed in the future )
Retractions
If the RRT member conclude that an event is NOT astrophysical origin, they issue a retraction circular with around 4 hours of latency. In the case of less urgency, this discussion may wait for the semi-regular call described below and issue a retraction there. (e.g. a BBH is found with high terrestial probability) (this is probably fluid and can be changed in the future )
Semi-regular call
We will have semi-regular calls of the full RRT, maximum of one per day as necessary, for several reasons.
- Vetting of BBH and terrestrial triggers, followed by initial or retraction circular.
- Follow up of all events handled by the RRT.
- Discussion of Sub-threshold events of interest.
- Handing off further follow-up of events to the appropriate group chairs.
- Ensuring that candidate statistics are recorded.
The active detector run managers for detectors participating in low-latency alerts will convene response calls as needed.
What the gstlal shift is supposed to do
- monitor an analysis (see Monitoring section for details)
- join the RRT call and subsequent semi-regular call
- perform event follow-up if necessary within 24 hours after the event time
GraceDb - how to find info, plots,
TBD
Event follow-up
During O3, we developed an semi-automated workflow to re-run a pipeline with a different configuration for a follow-up of a particular event when necessary. This happened, for example, when we found one of the detectors was online but technically not science mode and still needed the data in the coincidence to get a better skymap.
Here is a Makefile. You just need to edit GID to be the event you want to re-analyze. (We will need to modify this Makefile to accommodate to the O4 pipeline.)
RRT flowchart
The original document can he found here
Examples
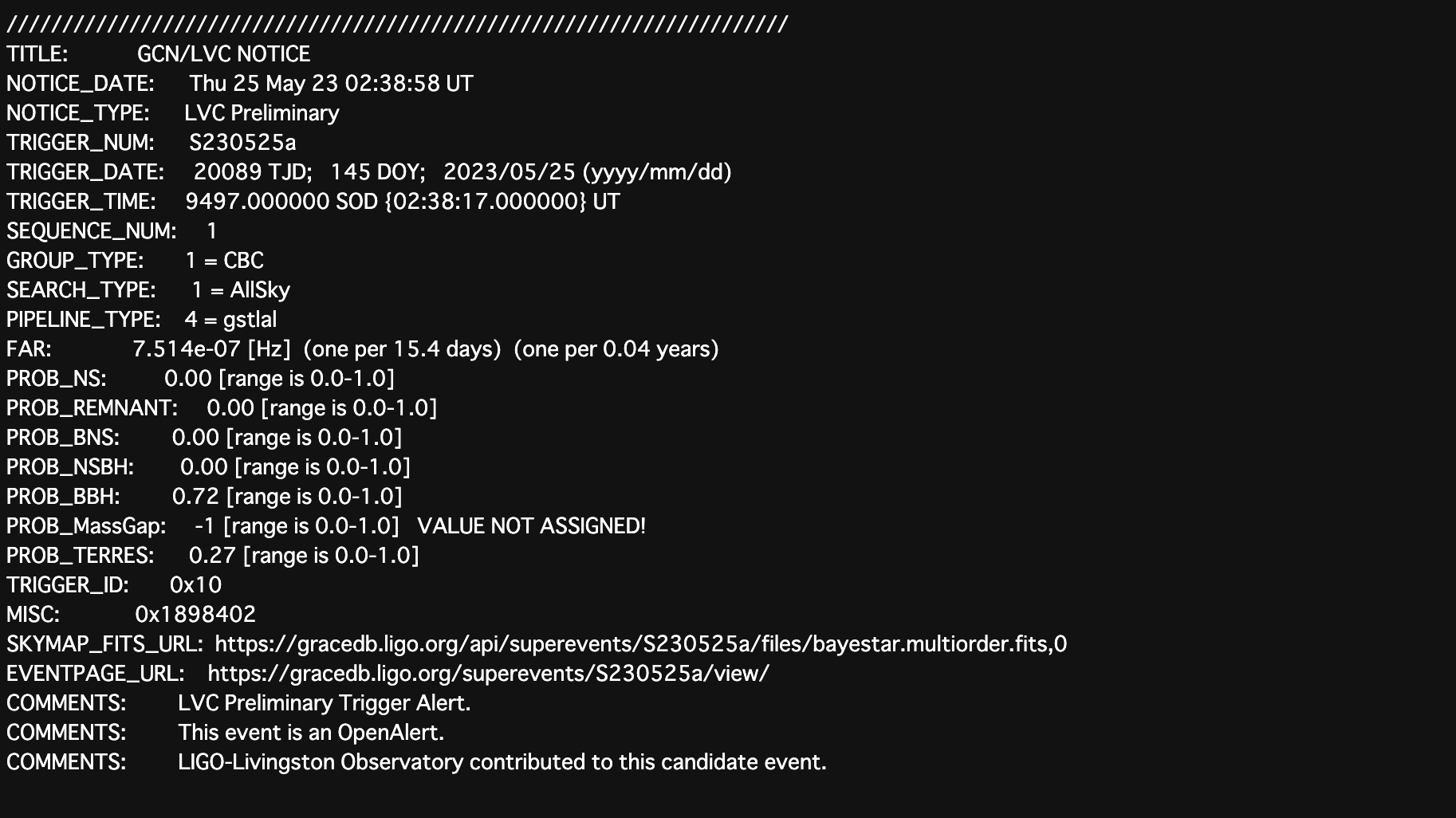
GCN Preliminary Notice
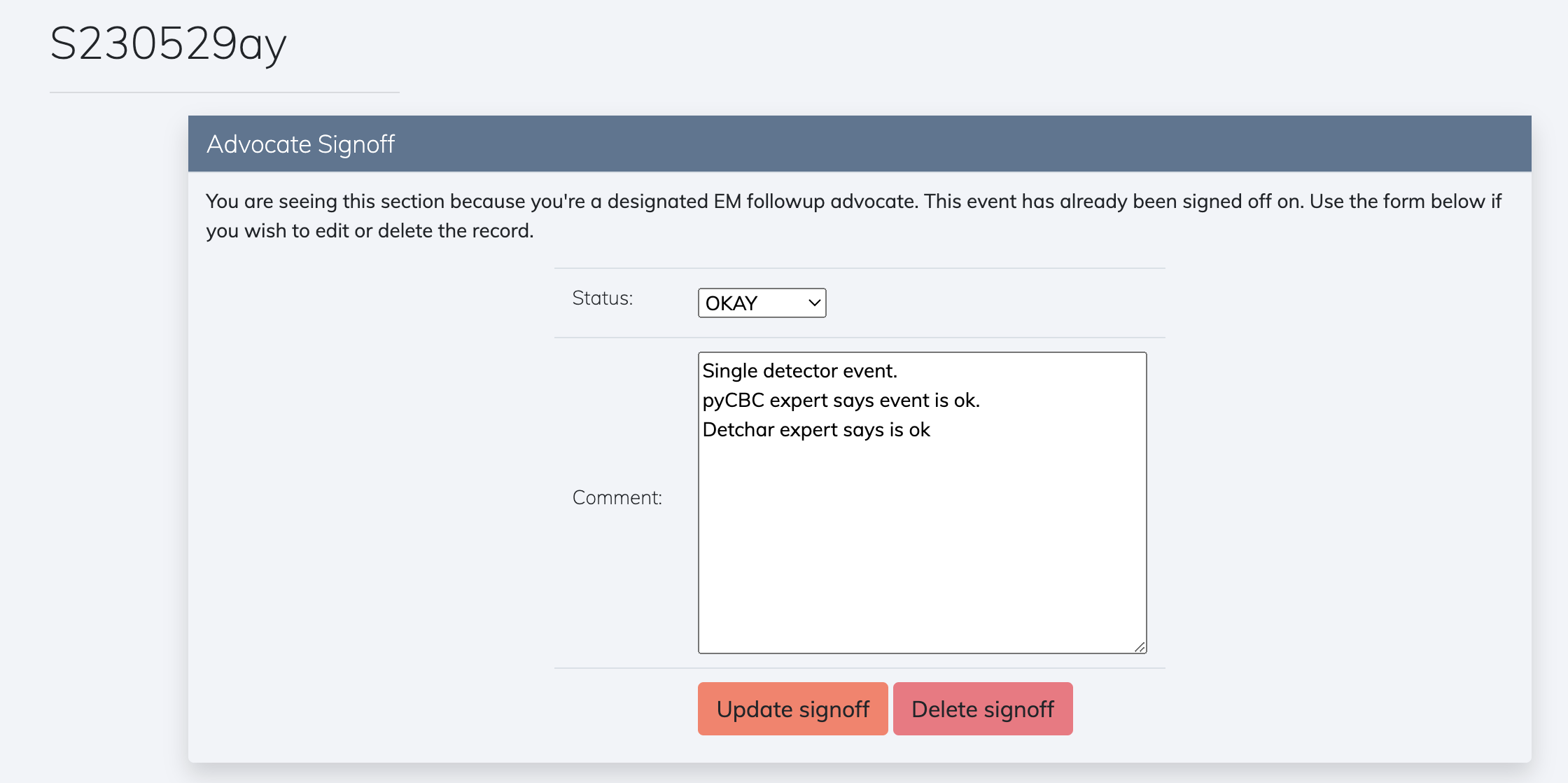
EM advocate signoff
GCN Initial Circular

Event Retraction
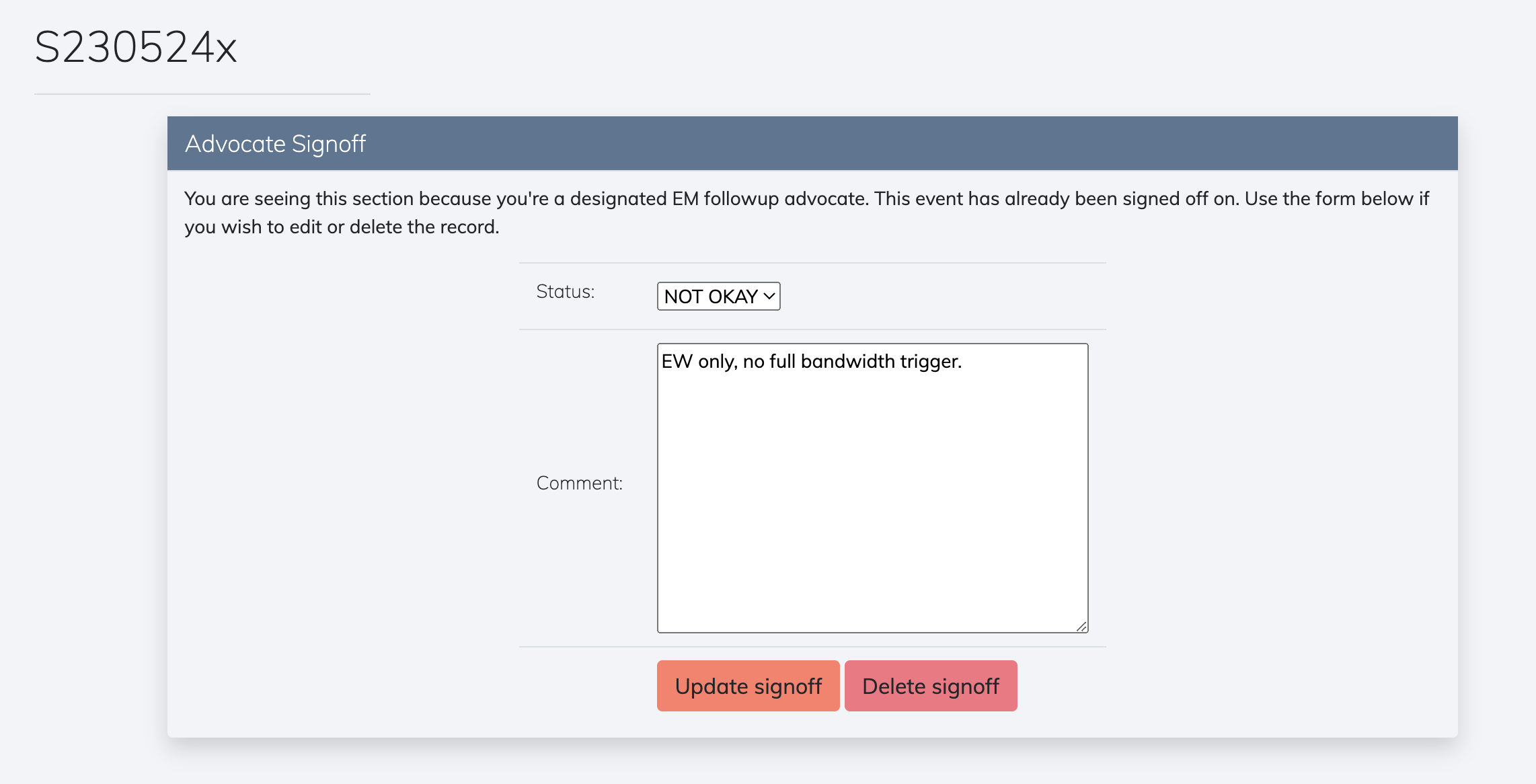
Retraction alert

Running bilby on GraceDB events
Online PE automatically runs on significant events (i.e. FAR < 1 per 10 months for All-sky and < 1 per 4 months for Early-warning after the trial factor) in GraceDB. However, if we want to see the PE results for low-significant events, we would have to perform a PE ourselves. Here describes step-by-step instructions of how to launch the bilby analysis for a given GraceDB event.
-
Install necessary packages For consistency with the online PE, you need to install
bilby==2.1.1andbilby_pipe==1.1.1. You can create a newcondaand install these packages inside the conda env. Alternatively, if you are lazy for setting this up, at CIT you can source the conda env withconda activate /home/leo.tsukada/conda-env/o4_pe_followup -
Download
coinc.xmlfrom a GraceDB entry Since the psd data inside thecoinc.xmlis necessary to set up a PE run, for example, for G-event with the identifierG999999runmkdir G999999 cd G999999 gracedb -s https://gracedb.ligo.org/api/ get file G999999 coinc.xml ./G999999_coinc.xmlNote that if you want events from playground or test version of GraceDB, change the server URL to be
https://gracedb-playground.ligo.org/api/orhttps://gracedb-test.ligo.org/api/. -
Set up an option file (
settings.json) to create a config file from You need to grab a json file that contains several options to generate a config file for bilby run. You can copy one of those stored in emfollow’s cache dir, e.g./home/emfollow/.cache/bilby/S230520ae/production/settings.jsonat CIT. Then you need to modify that as follows:- replace
"accounting_user": "soichiro.morisaki"with your ligo.org username - replace
"gracedb": "G407622"with"gracedb": "G999999" - delete
"queue": "Online_PE", - reduce
npoolandrequest_cpusto 12.
- replace
-
Run
bilby_pipe_gracedbInsideG999999/, runbilby_pipe_gracedb \ --gracedb G999999 \ --psd-file ./G999999_coinc.xml \ --outdir ./run/ \ --output ini \ --cbc-likelihood-mode lowspin_phenomd_fhigh1024_roq \ --settings ./settings.jsonThis will create
run/in the current directory and generate all the necessary files, such asbilby_config.iniandonline.prior. Note that--cbc-likelihood-modeneeds to be adjusted based on the trigger value of chirp mass. It should be determined by the following logic:if trigger_chirp_mass < 1.465: lowspin_phenomd_fhigh1024_roq elif trigger_chirp_mass < 2.243 phenompv2_bns_roq elif trigger_chirp_mass < 12: low_q_phenompv2_roq else: phenomxphm_roqTODO : this workflow needs to be automated as Makefile.
-
Modify the config and prior file You need to modify a few places in these two files.
online.prior:-
The upper bound of distance prior is by default 5Gpc, but sometimes an event in question might have an extend distance estimate beyond that. Check the distance estimate by Bayestar in a superevent page, e.g. the top right panel of this plot:
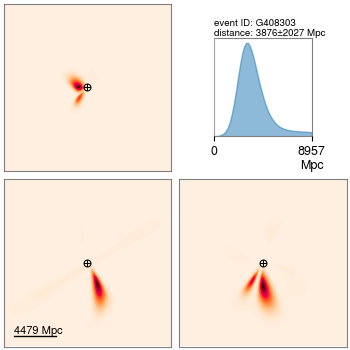
Then replace the upper bound of the distance prior with the upper bound of the x-axis of the panel.
bilby_config.ini:- delete
distance-marginalization-lookup-table=... - add
create-summary=True. This will add a job to generatePESummarypage
-
-
Run
bilby_pipeand submit a dag With all the necessary files given, runbilby_pipe run/bilby_config.ini --submitNote that
--submitwill the dag be submitted automatically, so you just need to start monitoring it. All the condor-related files live underrun/submit/. Note that a “dag” file in this case is named asrun/submit/dag_G999999.submitand you can monitor the progress by runningtail -f run/submit/dag_G999999.submit.dagman.outIn general, a bilby dag has the following dependence among jobs:
- data generation job
- -> a couple of independent sampling jobs
- -> merge job
- -> post-processing job
- ->
PESummaryjob
-
View a
PESummarypage The path to a relevant html page isrun/results_page/home.html. Open the file with a browser, and then you will see something like this.
You can take a look at this page here.